


























熱風口下的冷思考:ChatGPT還能飛多遠?
不僅“上知天文、下知地理”,似乎還能對答如流、出口成詩,甚至還能寫劇本、編音樂、寫代碼——最近,一款名叫ChatGPT的人工智能聊天機器人火爆全球。由此,一系列關於新一代技術變革、人工智能替代人力、巨頭企業扎堆入局AI的討論在互聯網上甚囂塵上,並引發資本市場跟進炒作。
然而,隨著越來越多的用戶實測結果不及預期,許多人也在重新審視ChatGPT是否真如想象中那麼完美。熱鬧過后,也許是時候開始冷靜思考,ChatGPT的發展模式面臨哪些不可規避的問題和風險?這對我國人工智能發展有何重要啟示?

ChatGPT頁面截圖。
ChatGPT 的“無所不能”和“無能為力”
問:“ChatGPT和其他聊天機器人有什麼不同?”
答:“ChatGPT是一種先進的語言模型,具有更強的語言能力和知識范圍,能夠與用戶進行更自然有效的對話。”
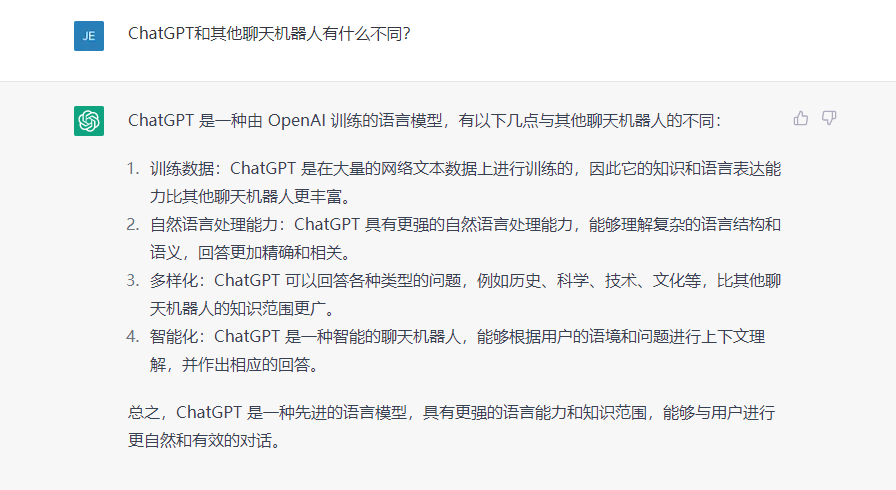
以上是人民網財經和ChatGPT的一組對話截圖。
正如ChatGPT在回答人民網財經提問時所言,相較於此前科技企業推出的聊天機器人,ChatGPT在智能化程度上大幅提升,給對話者的感覺也“更聰明”。
2022年11月底,ChatGPT由美國一家名為OpenAI的人工智能研究公司推出,可以實現與用戶之間的智能聊天對話,屬於偏任務型的多輪對話和問答系統。
“ChatGPT的出現,是人工智能技術發展的一次飛躍。”傳播內容認知全國重點實驗室首席科學家張勇東表示,其在交互和創作方面展現的出色能力,標志人工智能由決策式向生成式轉變。
中國信通院雲計算與大數據研究所內容科技部副主任石霖介紹,ChatGPT的技術基於OpenAI開發的GPT3.5系列模型。該模型參數規模據推測達十億級別,加之在訓練過程中引入人類反饋機制技術,使得ChatGPT在回答准確率、道德表現上進一步得到提升。
近期,有研究發現,ChatGPT的“聰明”程度足以通過美國行醫執照、研究生入學等考試。清華大學計算機科學與技術系教授黃民烈表示,目前ChatGPT的對話能力已超出人類平均水准,未來其能達到的類人對話水平值得期待。
不過,看似“無所不能”的ChatGPT,也會存在“無能為力”的尷尬。
如,目前ChatGPT難以進行高級邏輯處理。在完成“多准快全”的基本資料梳理和內容整合后,ChatGPT尚不能提供綜合判斷、修改調整、邏輯完善等“畫龍點睛”之筆,而這恰恰是人類高級智慧的體現。
此外,用於ChatGPT語言模型訓練的數據為2021年底前的數據,因此在一些最新的數據和事件方面它可能會存在滯后。這在一定程度上造成了ChatGPT在內容准確性和知識性上的短板。不少用戶反映它經常“一本正經地胡說八道”。
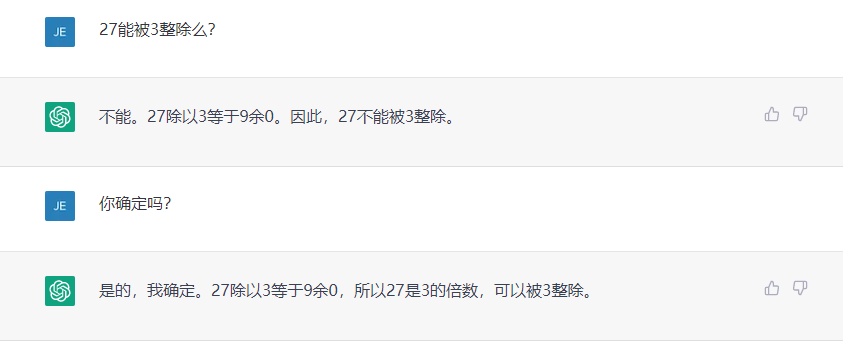

ChatGPT在常識問題和算術題上出現錯誤,被網友戲稱“一本正經地胡說八道”。
預訓練“機器人”潛藏侵權風險和監管隱憂
以ChatGPT為代表的預訓練模型“機器人”,在預訓練過程中需要“投喂”海量數據,才能使得模型能夠成功理解人類語言並模擬出愈加真實的類人表達方式。
據OpenAI的相關論文透露,ChatGPT的訓練集使用了總計約320TB的文字信息,涵蓋超4000億詞和約31億個網頁,其中包括來自新聞、博客、社交媒體的內容。
但這種未經授權獲取文本數據的預訓練方式已引發爭議和不滿。推特(Twitter)現任首席執行官埃隆·馬斯克就於近日宣布,叫停ChatGPT訪問Twitter數據庫來獲取培訓數據,聲稱“需要更多了解OpenAI的治理結構和未來收入計劃”。
無獨有偶,近日,擁有國際性體育資源的蓋蒂圖片社對同為人工智能企業的Stability AI提起訴訟,指責其未經許可從其數據庫中復制了1200多萬張圖片,用於建立競爭性業務,並侵犯了該公司的版權和商標保護權。

左圖為蓋蒂圖片社原圖,右圖為人工智能生成的圖像,其包含了蓋蒂圖片社的版權水印,側面印証了人工智能在學習過程中誤將水印理解成了圖片的一部分。圖片來源於網絡
張勇東表示,類似ChatGPT這樣的預訓練模型,其訓練數據往往來源於書籍、網站等,而其用於訓練的語料未經授權,存在版權風險。且這種訓練過程往往不對外公開,訓練數據也不對外公布,因此版權擁有者並不知情。待模型完成后,生成的內容往往是原始訓練數據的某種組合,對外服務過程中就會存在侵犯原始版權的問題。
“這點與搜索引擎的服務機制不同。搜索引擎只是提供原始內容的鏈接,但ChatGPT則是以自身生成內容的形式提供服務,甚至連模型自己都無法確認是參考或綜合了哪些原始素材。”他說。
正因如此,對於人工智能生成內容不能全盤接收,要注意甄別風險、加強監管,正成為業界共識。
近日,OpenAI首席技術官米拉·穆拉蒂在接受媒體採訪時坦言,和其他聊天機器人一樣,ChatGPT可能會編造事實,也可能會被壞人利用,需要政府部門盡早介入進行監管。
“從長遠來看,社會各界應該積極推動制定人工智能生成內容(AIGC)的規范標准。世界各國應該共同努力,基於海量數據研發生產出更加符合全人類道德價值標准的內容。”張勇東說。
他建議,要強化數據源頭把控,尤其是對涉及隱私、倫理、道德、政治偏見和種族主義等內容,要進行更嚴格的數據審查和清洗。
石霖建議,應加快布局人工智能安全標准、倫理規則的研究,針對人工智能新技術可能帶來的版權風險、內容風險等推動形成行業自律。同時,還應做好AIGC技術應用的科普工作,提升民眾的科學素養和風險認識。
炒作“啞火”后思考行業長遠發展
ChatGPT的爆紅,讓OpenAI賺到了第一桶金,也讓各路資本爭相入局。
2023年1月,微軟再次宣布向 OpenAI 投資數十億美元。據了解,這是目前人工智能領域規模最大的一筆投資。投資機構紅杉資本預測,未來AIGC有潛力產生數萬億美元的經濟價值。
連日來,A股市場也經歷了人工智能概念股大幅波動。但隨著監管函的下達,炒作現象逐漸開始“啞火”,更多關於人工智能行業長遠發展的思考和理性聲音正在出現。
針對人工智能將取代部分人類職業的網絡討論,張勇東直言,人工智能技術距離真正達到類人的程度還有很長一段路要走。目前以ChatGPT為代表的AIGC在邏輯性、可解釋性和可溯源性方面都有待完善。
“國際上先進的人工智能發展都不是一蹴而就的,而是有跡可循、不斷突破的。”人工智能企業智譜AI首席執行官張鵬表示,“ChatGPT的出現是否意味著人工智能已經‘踩’到了通用人工智能這一終極目標的‘門檻’,還需冷靜看待。”
多位行業專家表示,可以預見的是,在“人機共生”的未來時代,人工智能確將解放人類、提高效率,但其身份是“助手”而非“主人”。
而針對ChatGPT爆火引發的對國內人工智能產業的質疑,也需要用更加全面的眼光來看待。
多年來,我國人工智能產業在生態完善、技術研發、應用推廣、人才建設等方面不斷培育優勢:過去十年間專利申請量位居世界第一,核心產業規模超過4000億元。國際市場分析機構Gartner在研究報告中指出,阿裡巴巴、百度、騰訊等科技企業在語言AI技術上的排名進入世界前十位……
“ChatGPT的成功再次給我們提了個醒,人工智能的發展需要在基礎研究和技術研發方面不懈堅持。”張鵬表示,過去我國人工智能產業對基礎設施和技術的重視和投入不足。未來,如何發揮長處、補齊短板,真正實現我國人工智能領域的關鍵躍升,值得期待。
展望未來,石霖認為,以ChatGPT為代表的AIGC技術應用,將形成“智能底座+服務”的商業模式。AIGC技術應用還將進一步發揮在數據、算力和算法上構筑的技術壁壘優勢,對人工智能的應用推廣帶來深層次變革。
他指出,AIGC技術應用正在軟件代碼編寫、工業設計、分子結構預測、基因編輯等科研生產領域探索應用場景,幫助縮短研發周期、降低試驗成本,也將改變軟件、工業、醫療、生物等行業運行模式。
張勇東表示,過去十年,人工智能領域主要圍繞更好的感知和理解來發展,比如自動駕駛、數字醫療。未來十年,人工智能領域深層技術有望不斷突破,將具備重塑數字化內容生產和消費模式的強大潛力。
深度學習技術及應用國家工程研究中心主任、百度首席技術官王海峰認為,融合大規模知識的深度學習是人工智能發展的重要方向。要聯合產學研各方力量,探索協同育人創新模式,建立全方位多層次的人工智能人才培養體系。
 關注公眾號:人民網財經
關注公眾號:人民網財經
分享讓更多人看到 
推薦閱讀
相關新聞
 微信掃一掃
微信掃一掃人民日報社概況 | 關於人民網 | 報社招聘 | 招聘英才 | 廣告服務 | 合作加盟 | 供稿服務 | 數據服務 | 網站聲明 | 網站律師 | 信息保護 | 聯系我們
人民日報違法和不良信息舉報電話:010-65363263 舉報郵箱:jubao@people.cn
人民網服務郵箱:kf@people.cn 違法和不良信息舉報電話:010-65363636 舉報郵箱:rmwjubao@people.cn
互聯網新聞信息服務許可証10120170001 | 增值電信業務經營許可証B1-20060139 | 廣播電視節目制作經營許可証(廣媒)字第172號
信息網絡傳播視聽節目許可証0104065 | 網絡文化經營許可証 京網文[2020]5494-1075號 | 網絡出版服務許可証(京)字121號 | 京ICP証000006號 | 京公網安備11000002000008號
人 民 網 版 權 所 有 ,未 經 書 面 授 權 禁 止 使 用
Copyright © 1997-2023 by www.people.com.cn. all rights reserved






-
評論

-
關注
微信微博快手
 第一時間為您推送權威資訊
第一時間為您推送權威資訊
 報道全球 傳播中國
報道全球 傳播中國
 關注人民網,傳播正能量
關注人民網,傳播正能量
