![]()
![]()


2014年07月28日09:53
【新聞鏈接】
東大新型二次電池利用固體內的氧分子,能量密度達到現行鋰離子電池7倍
聯發科推出智能手機用64位八核LTE處理器,與高通的價格競爭激化
2014年6月底,台灣世芯電子(Alchip Technologies)宣布,與日本東京工業大學、一橋大學、會津大學共同開發出了單位功率的運算性能(電效率)為30GFLOPS/W*、達到全球最高水平的“PACS-G處理器芯片”。該處理器芯片是加速器(加速處理器)的一種,電效率比已有的微處理器及圖形處理單元(GPU)高5∼10倍。
*FLOPS(floating-point operations persecond)=1秒鐘可執行的浮點運算的次數。
瞄准新一代超級計算用途開發
PACS-G處理器以實現日本文部科學省推進的“后京”超級計算機(HPCI)、也就是100P∼數千P FLOPS的HPCI為目標而試制的,是HPCI的選項之一。
在開發HPCI時,研究人員每次都出現的爭論是在何種計算中最能發揮性能。為指定的計算用途優化系統容易以較少的開發費用來實現出色的性能,但缺乏通用性。相反,如果重視通用性,則往往會出現開發費用增大而性能平平的情況。
因此,日本文部科學省在2013年度之前,將后京HPCI要達到的要件分為與計算類型對應的4大類,按照各類同步實施了HPCI的性能評測。這4大類為:(1)存儲重視型、(2)通用目的型、(3 )存儲削減型、(4)運算重視型(圖1)注1)。
注1)HPCI的分類經常使用內存及內存帶寬與運算性能的比值。其中,存儲帶寬 (Bandwidth)與運算性能(FLOPS)的比值、即“B/F”尤其常用。(1)多指B/F值為2以上的系統,(2)多指B/F值為0.1左右的系 統,(3)多指B/F值為0.1∼1的系統,(4)多指B/F值為0.01以下的系統。
 |
|
圖1:瞄准重視運算性能的計算領域推進開發 在以日本文部科學省等推進的“后京”為目標的高性能運算系統(HPCI)的開發中,成為驗証對象的運算系統瞄准是,運用加速器(加速處理器)、相比運算量而言存儲容量較少、或者存儲帶寬較窄也可的、這一類型的計算。目標是由此實現出色的電效率。 |
直接利用內存數據
在這些類型中,PACS-G的目標是涵蓋(3 )和(4)兩種。這兩種類型最重視運算性能,相同點是相比運算性能而言存儲容量相對較少,並且容易提高電效率。
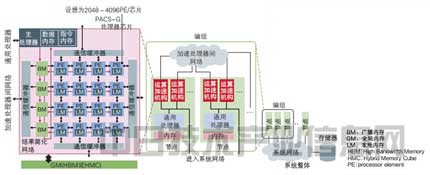
此次試制的是設想具備2048∼4096個內核(PE)的芯片的一部分,隻由32個處理單元(PE)和廣播內存(BM)構成(圖2、圖 3)。前工序利用台積電(TSMC)的流片服務(Shuttle Service,以低價格試制5個∼100個少量芯片的服務),以28nm工藝技術制作芯片。
 |
|
圖2:在各內核中配備可尋址內存 成為開發原案的系統和加速處理器“PACS-G處理器”的構成。加速處理器構成獨自的處理器網絡。另外,各加速處理器由2048∼4096個處理器內核 (PE)構成。各PE中封裝有可尋址的本地內存。全局內存使用HBM及HMC等堆棧內存,不使用DDR接口的DIMM等以往的外置內存。 |
 |
|
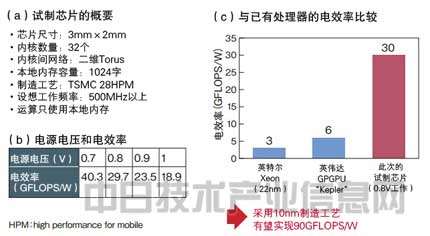
圖3:在不使用全局內存的情況下以低電壓驅動實現出色的電效率 對圖2中的加速處理器的一部分進行試制后,對電效率實施評測的結果。計算隻用本地內存來執行。以0.9V左右的低電壓驅動,降低了功耗。電效率在0.9V標准電壓下達到約24GFLOPS/W,以0.8V驅動時達到約30GFLOPS/W。 |
其特點有兩個。一是各內核封裝有可尋址的片上內存“本地內存(LM)”,二是可不通過寄存器直接將LM的數據用於運算數據(操作數)。這與RISC型微處理器採用的“載入和儲存架構(Load/Store Architecture)”不同。設計此次芯片的原東京工業大學教授、現日本理化學研究所粒子模擬器研究小組負責人牧野淳一郎等表示,“可大幅減少寄存器堆的訪問接口數量,對降低功耗有很大的效果”。
牧野表示,對於電力性能的提高,此次使用的漏電流小的移動用晶體管也做出了貢獻。如果設想採用10nm工藝技術,還有望實現50G∼90GFLOPS/W的電效率。(作者:野澤 哲生,日經技術在線!供稿)
