![]()
![]()


2013年08月27日09:45
【相关新闻】
三星向美国市场投放6.3英寸大屏智能手机“Galaxy Mega”
日本富士通研究所和北京富士通研究开发中心开发出了一种通过模拟人脑活动进行学习的手写汉字识别技术。通过开发该技术,有望针对各种合同文件等,提高手写文本数字化录入工作的效率。
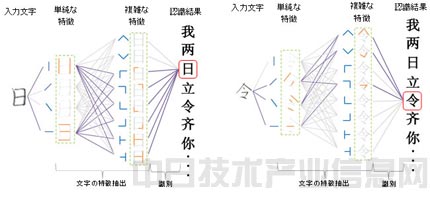
此次的分层网络模型的基本原理图。
富士通研究所称,传统的手写汉字识别技术是把笔画的方向和数量信息作为文字的特征,由此来识别每个字,但存在的问题是,无法识别变形较大的文字,而且,通过“学习”来提高识别精度是个非常耗时的过程。
关于文字识别必需的数据学习,此次的新技术使用的是与人脑内部细胞架构类似的分层神经元网络模型。对文字的特征从简单到复杂地分层提取,像人类记忆文字的过程那样捕捉文字的特征,不断积累学习成果。识别时,根据学习到的文字特征,通过分析哪一特征对输入的文字做出了反应得到识别结果并输出。
研究人员使用并行处理能力强的GPU(图形处理单元)来构筑学习数据,将传统方法需要4个月的学习时间缩短到了约一周。此次技术在第12届文档分析与识别国际会议(ICDAR2013 : International Conference on Document Analysis and Recognition)主办的手写汉字识别比赛中获得了第一名,以94.8%的文字识别精度刷新纪录。(日经技术在线! 供稿)
