![]()
![]()


2013年08月27日09:45
【相關新聞】
三星向美國市場投放6.3英寸大屏智能手機“Galaxy Mega”
日本富士通研究所和北京富士通研究開發中心開發出了一種通過模擬人腦活動進行學習的手寫漢字識別技術。通過開發該技術,有望針對各種合同文件等,提高手寫文本數字化錄入工作的效率。
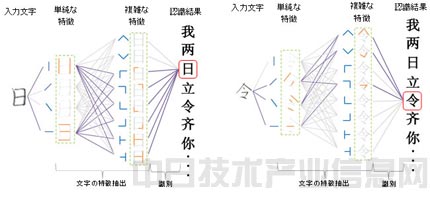
此次的分層網絡模型的基本原理圖。
富士通研究所稱,傳統的手寫漢字識別技術是把筆畫的方向和數量信息作為文字的特征,由此來識別每個字,但存在的問題是,無法識別變形較大的文字,而且,通過“學習”來提高識別精度是個非常耗時的過程。
關於文字識別必需的數據學習,此次的新技術使用的是與人腦內部細胞架構類似的分層神經元網絡模型。對文字的特征從簡單到復雜地分層提取,像人類記憶文字的過程那樣捕捉文字的特征,不斷積累學習成果。識別時,根據學習到的文字特征,通過分析哪一特征對輸入的文字做出了反應得到識別結果並輸出。
研究人員使用並行處理能力強的GPU(圖形處理單元)來構筑學習數據,將傳統方法需要4個月的學習時間縮短到了約一周。此次技術在第12屆文檔分析與識別國際會議(ICDAR2013 : International Conference on Document Analysis and Recognition)主辦的手寫漢字識別比賽中獲得了第一名,以94.8%的文字識別精度刷新紀錄。(日經技術在線! 供稿)
